
# Elasticsearch
# 参考文档
- Elasticsearch Docs (opens new window)
- Elasticsearch 中文文档 (opens new window)
- Elasticsearch RestClient Doc (opens new window)
# 可视化界面
Kibana- 浏览器插件
Multi Elasticsearch Head
# 简介
Elasticsearch 是 ELK 的核心,主要负责存储、搜索、分析数据。
ELK,即 Elastic stack。是以 Elasticsearch 为核心的技术栈,包括用于数据可视化的 Kibana,用于存储、计算、搜索数据的 Elasticsearch,用于数据抓取的 Logstash、Beats 等。
Elasticsearch 是一个 分布式 文档储存 搜索引擎(中间件),可以用来实现搜索、日志统计、分析、系统监控等功能。
它不会将信息储存为列数据行,而是储存已序列化为 JSON 文档的复杂数据结构。基于 Lucene(Java 语言的搜索引擎类库)。
ES 仅支持 JSON 格式数据。
# 存储过程
ES 存储数据时,会按照分词器,将需要存储的内容分成词条,然后以词条作为索引,索引对应的数据就是完整数据的 Id。
查询时,比如搜索华为手机,会将搜索条件分成 ‘华为’ 和 ‘手机’ 2 个词条,并分别去查询,查到的所有 Id 合并去重,如果 Id 结果集中有重复 Id 值,那么这一条数据的优先级会提升。
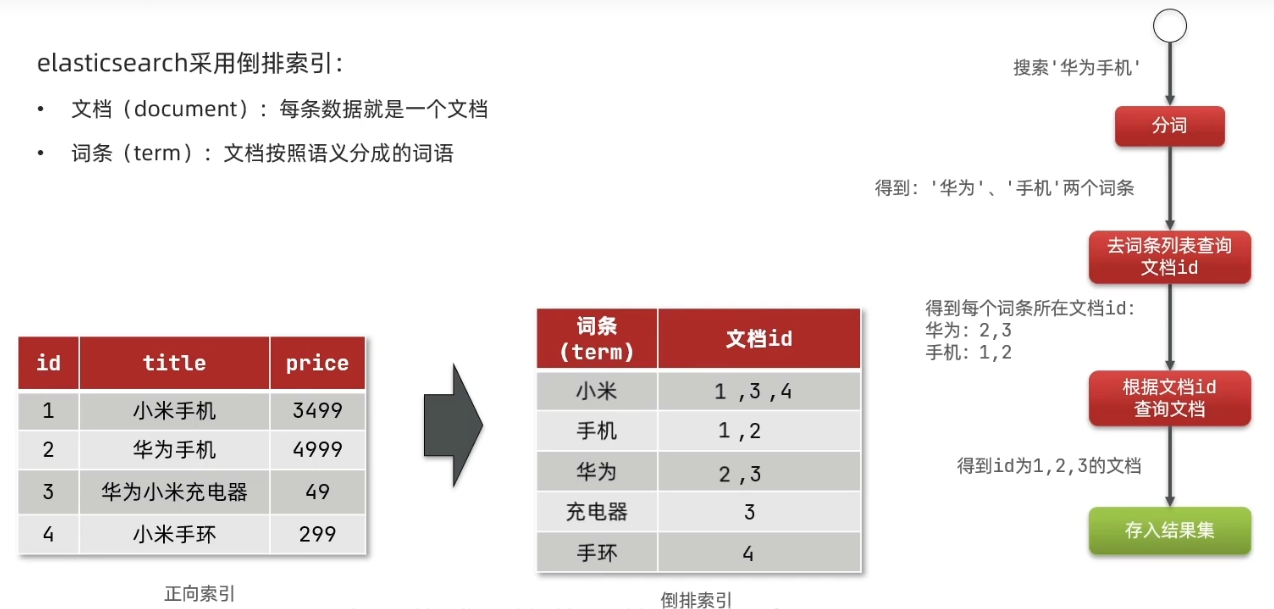
# 基本概念
相比于 MySQL 数据库,ES 的概念如下:
- 数据结构
- Index(索引) -> Database(数据库)/Table(表)
- Type(类型) -> Table(表)
Type 类型在 Elasticsearch 7.0 中被完全移除 - Document(文档) -> 一条数据
- Fields(字段)
- 查询方式
- SQL -> DSL
ES 是提供了一套 RESTful 的 http 接口来操作数据,而 DSL 就是 elasticsearch 提供的 JSON 风格的请求语句,用来操作 elasticsearch,实现 CRUD。
# 倒排索引
倒排索引是
Lucene的特点,ES 是封装了Lucene。
正向索引 forward index 是通过索引查询数据内容,反向索引 inverted index 是通过数据的内容查找索引,再去查出数据。
# 分词器
分词接口语法:
POST /_analyze
{
// 分词器类型,默认是标准分词器
"analyzer: "standard",
// 需要分词的内容
"text": "你好啊Java程序猿"
}
2
3
4
5
6
7
# IK 分词器
ElasticSearch 内置了分词器,如标准分词器、简单分词器、空白词器等。但这些分词器对我们最常使用的中文并不友好,不能按我们的语言习惯进行分词。
IK 分词器下载地址 (opens new window),下载时注意要和 ES 版本保持一致。
IK 分词器是一个标准的中文分词器。它可以根据定义的字典对域进行分词,并且支持用户配置自己的字典,所以它除了可以按通用的习惯分词外,我们还可以定制化分词。IK 分词器是一个插件包,我们可以用插件的方式将它接入到 ES。可以下载解压后,放在 es 的 plugins 目录下,重启 es 即可。
IK 分词器有两种模式:
ik_smart,最少切分ik_max_word,最细切分
假如对 “程序员” 进行分词,ik_smart 模式下,只会有一个结果 程序员,而使用 ik_max_word 模式,会被分成 程序员、程序、员 三个词。最少切分即从整个字符串开始判断,一旦可以分词之后,就不会继续向下判断了,而最细切分,则会一直切分到不能切分为止。
# 字典配置
Dictionary Configuration (opens new window),修改 analysis-ik/config 目录下的 IKAnalyzer.cfg.xml。文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!-- 用户可以在这里配置自己的扩展字典 -->
<!-- entry 标签声明的文件名,该文件需要放在该配置文件的同目录下 -->
<entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic</entry>
<!-- 用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
<!-- 用户可以在这里配置远程扩展字典 -->
<!-- 这里的 location 是一个 URL -->
<entry key="remote_ext_dict">location</entry>
<!-- 用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">http://xxx.com/xxx.dic</entry>
</properties>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 健康状态-DSL
查看详细状态信息:GET /_cat/indices?v
# 索引库操作-DSL
索引库等同于其他数据库的 schema。
# mapping
mapping 是对索引库中文档的约束,常见 mapping 属性如下:
type,字段数据类型- 字符串:
text,可分词文本;keyword,精确值 - 数值:long、integer、short、byte、double、float
- 布尔:boolean
- 日期:date
- 对象:object
- 字符串:
index,是否创建索引,默认为 trueanalyzer,指定分词器properties,该字段的子字段copy_to,可以将值拷贝到一个字段中(并非真实拷贝)
# 创建索引库
创建索引库语法:
PUT /索引库名称
{
"mappings": {
"properties": {
"字段名1": {
"type": "text",
// text 类型字段不指定分词器,默认用 standard
"analyzer": "ik_smart"
},
"字段名2": {
"type": "keword",
// 不创建索引,即不参与搜索
"index": "false"
},
"字段名3": {
"type": "object",
"properties": {
"子字段名1": {
"type": "text",
"analyzer": "ik_smart"
},
}
},
// ...
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 查看、删除索引库
查看语法:GET /索引库名
删除语法:DELETE /索引库名
# 修改索引库
索引库和 mapping 一经创建是不支持修改的,但是可以添加新的字段,语法为:
PUT /索引库名/_mapping
{
"properties": {
"新字段": {
type: "long"
}
}
}
2
3
4
5
6
7
8
# 文档操作-DSL
# 创建文档
添加数据语法:
// 如果文档 id 不传,es 会生成随机 id
// 使用同一个 id 进行创建的话,version 会递增。
POST /索引库名/_doc/文档id
{
"name": "Mario",
"age": 18,
// ...
}
2
3
4
5
6
7
8
# 查看、删除文档
- 查看索引库中所有数据:
GET /索引库名/_search - 查看语法:
GET /索引库名/_doc/文档id - 删除语法:
DELETE /索引库名/_doc/文档id
# 修改文档
添加数据语法:
// 全量修改,会将旧数据删除,按照同一 ID 创建
// 数据不存在,会新增数据
PUT /索引库名/_doc/文档id
{
"name": "Mario",
"age": 18,
// ...
}
// 局部修改
PUT /索引库名/_update/文档id
{
"doc": {
"name": "Mario修改后",
// ...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 文档查询-DSL
语法:
GET /索引库/_search
{
"query": {
"查询类型": { // 例如 match、match_all
"filedName": "value"
}
}
}
2
3
4
5
6
7
8
DSL Query 主要有以下几类:
- 查询所有,
match_all - 全文检索查询(full text),利用分词器对用户输入的内容分词,然后去倒排索引库匹配。
matchmulti_match
- 精确查询,根据精确词条查找数据,一般是查找 keyword、数值、日期、boolean 等类型字段。
idsrangeterm
- 复合查询(compound),复合查询可以将以上各种条件组合起来,合并查询条件。
boolfunction_score
- 地理查询
# match* 查询
使用
match_all查询所有数据:GET /索引库/_search { "query": { // match_all 全量查询 "match_all": {} }, // 分页从 0 开始 "from": 0, "size": 1, "_source": ["想要返回的 field"], "sort": [ { "fieldName": "asc" } ] }1
2
3
4
5
6
7
8
9
10
11
12
13
14使用
match查询所有数据,match是全文查询中的一种,会对用户输入内容分词去查:GET /索引库/_search { "query": { // match 全量查询 // 一个 match 里面只能有一个条件(field) "match": { "name": "mario" } } }1
2
3
4
5
6
7
8
9
10使用
multi_match可以同时查询多个字段,和match类似:GET /索引库/_search { "query": { // 参与字段越多,性能越差,此处可以使用 copy_to 拷贝到 all 中,使用 all 一个字段进行查询 "multi_match": { "query": "mario", "fields": ["name", "nickname" ...] } } }1
2
3
4
5
6
7
8
9
10
# 精确查询
精确查询,根据精确词条查找数据,一般是查找 keyword、数值、日期、boolean 等类型字段,所以不会对搜索条件分词。
使用
term根据精确值查询:GET /索引库/_search { "query": { "term": { "brand": { "value": "nike" } } } }1
2
3
4
5
6
7
8
9
10使用
range根据值的范围查询,可以是数值或者时间:GET /索引库/_search { "query": { "range": { "age": { "gte": 20, "lte": 35 } } } }1
2
3
4
5
6
7
8
9
10
11
# 复合查询
# Boolean Query
布尔查询是一个或多个查询子句的组合。子查询的组合方式有:
must,相当于and,必须匹配每个子查询。should,相当于or,选择性匹配。must_not,相当于非,必须不匹配,不参与算分。filter,必须匹配,不参与算分。
示例:
{
"query": {
// bool 可以组合多个查询条件
"bool": {
// must = and, should = or
"must": [
// 条件 1
{
"match": {
// 一个 match 里面只能有一个条件(field)
"name": "aaa"
}
},
// 条件 2
{
"match": {
"age": 18
}
}
],
"filter": {
"range": {
"k": {
"gt": "ddd"
}
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# function score
// TODO
# 地理查询
// TODO
# 查询结果处理
# 排序 sort
ES 默认根据相关度算分来排序,但是可以手动指定排序字段(手动指定后,ES 不再打分),可以排序的字段类型有 keyword、数值、geo、日期等。
GET /索引库/_search
{
"query": {
"match_all": {}
},
"sort": [
{
// 取值有 asc 和 desc
"fieldName": "desc"
},
{
"fieldName1": "asc"
},
]
}
// 另一种写法(不推荐)
GET /索引库/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"fieldName": {
"order": "desc"
}
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 分页
ES 默认只返回查询结果的前 10 条数据,如果要查询更多就要指定分页参数。
GET /索引库/_search
{
"query": {
"match_all": {}
},
// 分页从 0 开始
"from": 0,
"size": 1
}
2
3
4
5
6
7
8
9
# 深度分页问题
ES 的数据结构决定了它的分页只能是查询全部再截取,例如 from 990, size 1, 这里只能是查询前 1000 条,然后截取 990-1000 这 10 条。
又因为 ES 是分布式的,如果有 10 台 ES,这时候需要将这 10 台 ES 中每一台的前 1000 条取出来,最后将这 10000 条数据聚合再排序,最后取前 1000。
如果集群中 ES 服务器很多的话,就会出现问题。所以如果搜索页数过深,或结果集(from+size)越大,对内存和 CPU 的消耗也就越高。
因此 ES 设定结果集查询上限为 10000,即所有机器数据加起来最多 10000 条。
ES 提供的 2 种解决方案:
search after,分页时需要排序,原理是从上一次的排序值开始,查询下一页的数据。(官方推荐方式)scroll,原理是将排序数据形成快照,保存在内存。(官方已不推荐使用)
# 高亮
高亮,就是在搜索结果中把搜索关键字突出显示。
原理就是 ES 将返回结果中的指定值添加 HTML 标签,然后前端再给这个标签编写 CSS 样式,最终显示的时候就是高亮效果啦。
我们需要做的就是告诉 ES 要 给哪些返回值添加哪些标签 就可以了。
GET /索引库/_search
{
"query": {
// 这里不能使用 match_all,因为要指定高亮的值,也就是这里查询的参数值,最终在返回时,会被高亮(打上标签)
"match": {
"name": "mario"
}
},
"highlight": {
// fields 中可以指定多个字段
"fields": {
"fieldName": {
"pre_tags": "<em>",
"post_tags": "</em>"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
高亮结果会单独在 "highlight" 中返回,手动替换掉 _source 中原来字段的值就可以了。
点开查看 默认值问题
// 1. 不指定 field 用哪个标签包裹,默认使用 <em></em>
// 2. 这里有可能是不会高亮的,因为这种默认情况下,只有在 搜索条件完全命中才会高亮,也就是返回结果中的值如果是 mario 才会返回 <em>mario</em>,如果是 mario1 就不会高亮了。
GET /索引库/_search
{
"query": {
// 这里不能使用 match_all,因为要指定高亮的值,也就是这里查询的参数值,最终在返回时,会被高亮(打上标签)
"match": {
"name": "mario"
}
},
"highlight": {
// fields 中可以指定多个字段
"fields": {
"fieldName": {
}
}
}
}
// 想要解决 2 问题的话,可以使用 require_field_match
GET /索引库/_search
{
"query": {
// 这里不能使用 match_all,因为要指定高亮的值,也就是这里查询的参数值,最终在返回时,会被高亮(打上标签)
"match": {
"name": "mario"
}
},
"highlight": {
// fields 中可以指定多个字段
"fields": {
"fieldName": {
// 指定不需要完全匹配结果才会高亮
"require_field_match": "false"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 聚合
// TODO
# RestClient
ES 官方提供了多种语言的客户端来操作 ES,这些客户端的本质就是组装 DSL 语句,通过 http 请求发送给 ES。
# 索引库操作-RestClient
// TODO
# 文档操作-RestClient
// TODO
# nested(待整理)
查询条件:type + user.name + user.age
数据结构:
{
"type": "people",
"users": [
{
"name": "xiaobai",
"age": 11
},
{
"name": "xiaoming",
"age": 12
}
]
},
{
"type": "alien",
"users": [
{
"name": "martin",
"age": 888
},
{
"name": "mark",
"age": 999
}
]
},
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
对应 Query:
{
"query": {
"bool": {
"must": [
{
"match": {
"type": "people"
}
},
{
"nested": {
"path": "users",
"query": {
"bool": {
"must": [
{
"match": {
"users.name": "xiaoming"
}
},
{
"match": {
"users.age": "12"
}
}
]
}
}
}
}
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 讨论区
由于评论过多会影响页面最下方的导航,故将评论区做默认折叠处理。