
# Java 基础
# 参考文档
# 基本数据类型
- Java 的数据类型一共有 2 种,一种是基本数据类型,另一种是引用数据类型。
- Java 有 8 大基本数据类型,如果不给初始值,Java 将赋值为
0、null、false。- 只有类的成员变量才会被初始化,局部变量是必须要手动设置一个初始值的。
- Java 中采用 Unicode 编码,它的汉字和字母都占用 2 个字节。
# 整数型
byteshortintlong
# 浮点型
floatdouble
# 字符型
char
# 布尔类型
boolean
# 输入输出
# 占位符
%d,格式化输出整数。%s,格式化字符串。%f,格式化输出浮点数。%e,格式化输出科学计数法表示的浮点数。%x,格式化输出十六进制整数。
# 面向对象
# 向上转型
- 子类可以调用覆写父类的方法,如果没有覆写,也可以调用父类的方法。
- 不可以调用子类独有的方法。
# this
this 始终指向当前实例,在类中
# 静态字段和静态方法
所有实例共享一个静态字段。
┌──────────────────┐ ming ──>│Person instance │ ├──────────────────┤ │name = "Xiao Ming"│ │age = 12 │ │number ───────────┼──┐ ┌─────────────┐ └──────────────────┘ │ │Person class │ │ ├─────────────┤ ├───>│number = 99 │ ┌──────────────────┐ │ └─────────────┘ hong ──>│Person instance │ │ ├──────────────────┤ │ │name = "Xiao Hong"│ │ │age = 15 │ │ │number ───────────┼──┘ └──────────────────┘1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 访问修饰符
private,当前 class 内。default,即包访问权限,当前包内。protected,当前包内 + 子类。public,任何位置。
# 关键字
# instanceof
// TODO
# Java 核心/常用类
# 可变长参数
public int sum(int a, int... b) {
int bsum = Arrays.stream(b).sum();
return a + bsum;
}
2
3
4
... 实质就是数组。
# String 类
String 类是使用 char[] 实现的。
字符串内容是不可变的,所有的对象都是不可变的,当一个对象变化的时候,实际上是直接将它的指针指向了一个新的对象。
从String的不变性设计可以看出,如果传入的对象有可能改变,我们需要复制而不是直接引用。
字符串的比较:
==比较的是内存单元的存储内容,equals比较的是对象的实际内容,也就是内存单元存储的指针指向的位置的内容,因为 String 是引用类型,所以使用equals进行比较内容。示例
String s1 = "hello"; String s2 = "hello"; System.out.println(s1 == s2) // true1
2
3
4Q:这里明明是声明了两个变量 s1 s2,原理上 s1 s2 这两个变量存储的是两个不同的指针,分别指向两个不同的地址,这两个地址内存储的都是 hello,但是为什么这里打印出来是 true。
A:因为 Java 在编译期会把所有的字符串当做一个对象放进常量池,所以它们的引用在这里就是一样的了。
String format
%d,占位一个数字%2d,数字占位两个空间,不足左侧补空格%.d,数字保留一位有效数字%.2d,数字保留两位有效数字,不足,左侧补零%02d,数字长度 2,不足左侧补零
# StringBuilder 类
- 避免重复创建新字符串
- 使用 StringBuilder 类,可以只开辟一块空间,操作完以后使用 toString() 将内容赋值给 s。
# Enum 类
enum类型的每个常量在JVM中只有一个唯一实例,所以可以直接用==比较:- 定义的
enum类型继承自java.lang.Enum,无法被继承; - 无法通过
new操作符创建enum的实例 - 定义的每个实例都是引用类型的唯一实例;
# BigDecimal 类
scale(),显示小数部分。setScale(),设置精度。RoundingMode.HALF_UP,四舍五入。RoundingMode.DOWN,直接截取。
注意: 比较大小 使用 compareTo(),不要使用 equals()。因为 BigDecimal 是由两部分组成的,一部分是整数部分,一部分是小数部分。
# 日志/异常处理
# 捕获异常
- 多
catch语句只会执行一条,遇到一个进去以后,就直接返回了。 - 子类写在前面。
catch (IOException | NumberFormatException e),异常之间使用|进行并列选择。
# NullPointerException
- 尽量初始化不要为
null。
# 断言 assert
- 格式:
assert x >= 0 : "error message"; - 断言失败时会抛出
AssertionError,导致程序结束退出。因此,断言不能用于可恢复的程序错误,只应该用于开发和测试阶段。
# 日志
日志就是 Logging,它的目的是为了取代 System.out.println()。
输出日志,而不是用 System.out.println(),有以下几个好处:
- 可以设置输出样式,避免自己每次都写
"ERROR: " + var; - 可以设置输出级别,禁止某些级别输出。例如,只输出错误日志;
- 可以被重定向到文件,这样可以在程序运行结束后查看日志;
- 可以按包名控制日志级别,只输出某些包打的日志;
- 等等
# JDK Logging
Java 标准库内置了日志包
java.util.logging。日志级别(从严重到普通):
SEVEREWARNINGINFO,默认级别CONFIGFINEFINERFINEST
# SLF4J 和 Logback
{},使用占位符。
# 注解(Annotation)
# 三类注解
编译器使用的
@Override@SuppressWarnings,告诉编译器忽略此处的代码产生的警告- 不会编译进 .class 文件
第二类,是由工具处理 .class 文件使用的注解,
- 比如有些工具会在加载 class 的时候,对 class 做动态修改,实现一些特殊的功能。这类注解会被编译进入 .class 文件,但加载结束后并不会存在于内存中。这类注解只被一些底层库使用,一般我们不必自己处理。
自定义
# 自定义注解
# Java 使用 @interface 语法来定义注解
格式:
public @interface Report { int type() default 0; String level() default "info"; String value() default ""; }1
2
3
4
5注解的参数类似无参数方法,可以用
default设定一个默认值(强烈推荐)。最常用的参数应当命名为
value。如果一个参数没有设置默认值的话,使用该注解的时候会提示必须给这个参数设置一个值。
# 元注解
@target,描述注解的适用范围(被修饰的注解可以用在什么地方)参数
- 类或接口:
ElementType.TYPE - 字段:
ElementType.FIELD - 方法:
ElementType.METHOD - 构造方法:
ElementType.CONSTRUCTOR - 方法参数:
ElementType.PARAMETER
- 类或接口:
示例:
例如,定义注解
@Report可用在方法上,我们必须添加一个@Target(ElementType.METHOD):@Target(ElementType.METHOD) public @interface Report { int type() default 0; String level() default "info"; String value() default ""; }1
2
3
4
5
6定义注解
@Report可用在方法或字段上,可以把@Target注解参数变为数组{ ElementType.METHOD, ElementType.FIELD }:@Target({ ElementType.METHOD, ElementType.FIELD }) public @interface Report { ... }1
2
3
4
5
6
7实际上
@Target定义的value是ElementType[]数组,只有一个元素时,可以省略数组的写法。
Retention,描述注解保留的时间范围(声明周期)- 3种策略
- 编译期:
RetentionPolicy.SOURCE - class 文件:
RetentionPolicy.CLASS - 运行期:
RetentionPolicy.RUNTIME
- 编译期:
- 3种策略
@Inherited,使得被它修饰的注解拥有继承性(如果某个类使用了被@Inherited修饰的注解,则其子类自动拥有该注解)- 注意:使用
@Inherited定义子类是否可继承父类定义的Annotation。@Inherited仅针对@Target(ElementType.TYPE)类型的annotation有效,并且仅针对class的继承,对interface的继承无效:
- 注意:使用
# 其它注解
- @AliasFor - Spring 的注解
# 泛型
# 使用泛型
- 例如
ArrayList使用泛型的时候,如果不加定义的话,默认传入的是 Object。
# 编写泛型
- 编写泛型类时,注意 不能用于静态方法。
# 擦拭法 - 实现方式
<T>不能是基本类型,例如int,因为实际类型是Object,Object类型无法持有基本类型。- 无法取得带泛型的
Class。 - 无法判断带泛型的类型。
- 不能实例化
T类型。
# extends 通配符
Pair<? extends Number>使得方法接收所有泛型类型为Number或Number子类的Pair类型。- 上面的写法可以称为上界通配符
(Upper Bounds Wildcards)
# super 通配符
Pair<? super Number>Number的父类都可以。
# PECS 原则
Producer Extends Consumer Super
# 无限制通配符 ?
<?>
# 集合
Collection,java.util 包提供的,是除 Map 以外的所有集合的根接口。
Java集合使用统一的Iterator遍历
# List
- 在末尾添加一个元素:
boolean add(E e) - 在指定索引添加一个元素:
boolean add(int index, E e) - 删除指定索引的元素:
E remove(int index) - 删除某个元素:
boolean remove(Object e) - 获取指定索引的元素:
E get(int index) - 获取链表大小(包含元素的个数):
int size()
# Map
作为
key的对象必须正确覆写equals()方法,相等的两个key实例调用equals()必须返回true;作为 key 的对象还必须正确覆写
hashCode()方法,且hashCode()方法要严格遵循以下规范:如果两个对象相等,则两个对象的
hashCode()必须相等;如果两个对象不相等,则两个对象的
hashCode()尽量不要相等。
# Enum Map
如果 key 是 enum 类型,使用 Java 集合库提供的 EnumMap,它在内部以一个非常紧凑的数组存储 value,并且根据 enum 类型的 key 直接定位到内部数组的索引,并不需要计算 hashCode(),不但效率最高,而且没有额外的空间浪费。
# Properties
- Properties 文件是
k-v,即String - String,格式的。 - Java 默认配置文件以
.properties为扩展名。 - 每行以
key = value表示,以#开头的是注释。
用 Properties 读取配置文件示例:
String f = "setting.properties";
Properties props = new Properties();
props.load(new java.io.FileInputStream(f));
String filepath = props.getProperty("last_open_file");
String interval = props.getProperty("auto_save_interval",s 120");
2
3
4
5
6
可见,用 Properties 读取配置文件,一共有三步:
- 创建
Properties实例; - 调用
load()读取文件; - 调用
getProperty()获取配置。
通过 setProperty() 修改了 Properties 实例,可以把配置写入文件,以便下次启动时获得最新配置。写入配置文件使用 store() 方法:
Properties props = new Properties();
props.setProperty("url", "http://www.liaoxuefeng.com");
props.setProperty("language", "Java");
props.store(new FileOutputStream("C:\\conf\\setting.properties"), "这是写入的properties注释");
2
3
4
# Set
常用方法:
- 将元素添加进
Set<E>:boolean add(E e) - 将元素从
Set<E>删除:boolean remove(Object e) - 判断是否包含元素:
boolean contains(Object e)
# Queue
Queue 实际上是实现了一个先进先出(FIFO:First In First Out)的有序表。它只支持:
- 从头部取出元素
- 从尾部添加元素
常用方法:
int size():获取队列长度;boolean add(E)/boolean offer(E):添加元素到队尾;E remove()/E poll():获取队首元素并从队列中删除;E element()/E peek():获取队首元素但并不从队列中删除。
# 日期与时间
# 时间转化问题
public static final DateTimeFormatter DATE_FORMATTER_MD = DateTimeFormatter.ofPattern("yyyy-M-d");
LocalDate localDate = LocalDate.parse(time, DATE_FORMATTER_MD);
2
- 使用
yyyy-M-d可以接收2021-1-1、2021-11-1、2021-01-01、2021-11-01等类型的值。 - 使用
yyyy-MM-dd不可以接收形如2021-1-1、2021-11-1、2021-11-01等类型的值。
# Java 时区问题
/etc/localtime是用来描述本机时间/etc/timezone是用来描述本机所属的时区
在 linux 中,有一些程序会自己计算时间,不会直接采用带有时区的本机时间格式,会根据 UTC 时间和本机所属的时区等计算出当前的时间。
比如 jdk 应用,时区为 Etc/UTC,本机时间改为北京时间,通过 java 代码中 new 出来的时间还是 utc 时间,所以必须得修正本机的时区。
# 本地化
- 在计算机中,通常使用
Locale表示一个国家或地区的日期、时间、数字、货币等格式。Locale由 语言_国家 的字母缩写构成,例如,zh_CN表示中文 + 中国,en_US表示英文 + 美国。语言使用小写,国家使用大写。 System.currentTimeMillis(),当前时间毫秒数,从 1970 年开始。
# API
- 一套定义在
java.util这个包里面,主要包括Date、Calendar和TimeZone这几个类; - 一套新的
API是在 Java 8 引入的,定义在java.time这个包里面,主要包括LocalDateTime、ZonedDateTime、ZoneId等。
# 旧 API
# (一)Date 类
java.util.Date 是用于表示一个日期和时间的对象,注意与 java.sql.Date 区分,后者用在数据库中。如果观察 Date 的源码,可以发现它实际上存储了一个 long 类型的以毫秒表示的时间戳:
- 不能转换时区,
Date总是以当前计算机系统的默认时区为基础进行输出。
public class Main {
public static void main(String[] args) {
// 获取当前时间:
Date date = new Date();
System.out.println(date.getYear() + 1900); // 必须加上1900
System.out.println(date.getMonth() + 1); // 0~11,必须加上1
System.out.println(date.getDate()); // 1~31,不能加1
// 转换为String:
System.out.println(date.toString());
// 转换为GMT时区:
System.out.println(date.toGMTString());
// 转换为本地时区:
System.out.println(date.toLocaleString());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
注意:
getYear(),返回的年份必须加上 1900。getMonth(),返回的月份是 0 ~ 11,分别表示 1 ~ 12 月,所以要加 1。getDate(),返回的日期范围是 1 ~ 31,又不能加 1。
SimpleDateFormat 可以对 Date 进行格式化转换。它用预定义的字符串表示格式化:
yyyy:年MM:月dd: 日HH: 小时mm: 分钟ss: 秒
示例:
public class Main {
public static void main(String[] args) {
// 获取当前时间:
Date date = new Date();
var sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
System.out.println(sdf.format(date));
}
}
2
3
4
5
6
7
8
# (二)Calendar 类
Calendar 可以用于获取并设置年、月、日、时、分、秒,它和 Date 比,主要多了一个可以做简单的日期和时间运算的功能。
public class Main {
public static void main(String[] args) {
// 获取当前时间:
Calendar c = Calendar.getInstance();
int y = c.get(Calendar.YEAR);
int m = 1 + c.get(Calendar.MONTH);
int d = c.get(Calendar.DAY_OF_MONTH);
int w = c.get(Calendar.DAY_OF_WEEK);
int hh = c.get(Calendar.HOUR_OF_DAY);
int mm = c.get(Calendar.MINUTE);
int ss = c.get(Calendar.SECOND);
int ms = c.get(Calendar.MILLISECOND);
System.out.println(y + "-" + m + "-" + d + " " + w + " " + hh + ":" + mm + ":" + ss + "." + ms);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
注意:
- 返回的月份是 0 ~ 11,要加 1。
- 返回的星期要特别注意,1 ~ 7 分别表示周日,周一,……,周六。
Calendar 只有一种方式获取,即 Calendar.getInstance(),而且一获取到就是当前时间。如果我们想给它设置成特定的一个日期和时间,就必须先清除所有字段:
public class Main {
public static void main(String[] args) {
// 当前时间:
Calendar c = Calendar.getInstance();
// 清除所有:
c.clear();
// 设置2019年:
c.set(Calendar.YEAR, 2019);
// 设置9月:注意8表示9月:
c.set(Calendar.MONTH, 8);
// 设置2日:
c.set(Calendar.DATE, 2);
// 设置时间:
c.set(Calendar.HOUR_OF_DAY, 21);
c.set(Calendar.MINUTE, 22);
c.set(Calendar.SECOND, 23);
System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(c.getTime()));
// 2019-09-02 21:22:23
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
注意:
- 利用
Calendar.getTime()可以将一个Calendar对象转换成Date对象,然后就可以用SimpleDateFormat进行格式化了。
# (三)TimeZone 类
Calendar 和 Date 相比,它提供了时区转换的功能。时区用 TimeZone 对象表示:
public class Main {
public static void main(String[] args) {
TimeZone tzDefault = TimeZone.getDefault(); // 当前时区
TimeZone tzGMT9 = TimeZone.getTimeZone("GMT+09:00"); // GMT+9:00时区
TimeZone tzNY = TimeZone.getTimeZone("America/New_York"); // 纽约时区
System.out.println(tzDefault.getID()); // Asia/Shanghai
System.out.println(tzGMT9.getID()); // GMT+09:00
System.out.println(tzNY.getID()); // America/New_York
}
}
2
3
4
5
6
7
8
9
10
- 时区的唯一标识是以字符串表示的 ID,我们获取指定
TimeZone对象也是以这个 ID 为参数获取。 GMT+09:00、Asia/Shanghai都是有效的时区 ID。- 要列出系统支持的所有 ID,请使用
TimeZone.getAvailableIDs()。
有了时区,我们就可以对指定时间进行转换。例如,下面的例子演示了如何将北京时间 2019-11-20 8:15:00 转换为纽约时间:
public class Main {
public static void main(String[] args) {
// 当前时间:
Calendar c = Calendar.getInstance();
// 清除所有:
c.clear();
// 设置为北京时区:
c.setTimeZone(TimeZone.getTimeZone("Asia/Shanghai"));
// 设置年月日时分秒:
c.set(2019, 6 /* 11月 */, 20, 8, 15, 0);
// 加5天并减去2小时:
c.add(Calendar.DAY_OF_MONTH, 5);
c.add(Calendar.HOUR_OF_DAY, -2);
// 显示时间:
var sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
sdf.setTimeZone(TimeZone.getTimeZone("America/New_York"));
System.out.println(sdf.format(c.getTime()));
// 2019-07-24 18:15:00
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
可见,利用 Calendar 进行时区转换的步骤是:
- 清除所有字段;
- 设定指定时区;
- 设定日期和时间;
- 创建
SimpleDateFormat并设定目标时区; - 格式化获取的Date对象(注意Date对象无时区信息,时区信息存储在
SimpleDateFormat中)。
因此,本质上时区转换只能通过 SimpleDateFormat 在显示的时候完成。
# 新 API
从 Java 8 开始,java.time 包提供了新的日期和时间 API,主要涉及的类型有:
- 本地日期和时间:
LocalDateTime,LocalDate,LocalTime; - 带时区的日期和时间:
ZonedDateTime; - 时刻:
Instant; - 时区:
ZoneId,ZoneOffset; - 时间间隔:
Duration。 - 以及一套新的用于取代
SimpleDateFormat的格式化类型DateTimeFormatter。
和旧的 API 相比,新 API 严格区分了时刻、本地日期、本地时间和带时区的日期时间,并且,对日期和时间进行运算更加方便。
此外,新 API 修正了旧 API 不合理的常量设计:
Month的范围用 1 ~ 12 表示 1 月到 12 月;Week的范围用 1 ~ 7 表示周一到周日。
最后,新 API 的类型几乎全部是不变类型(和 String 类似),可以放心使用不必担心被修改。
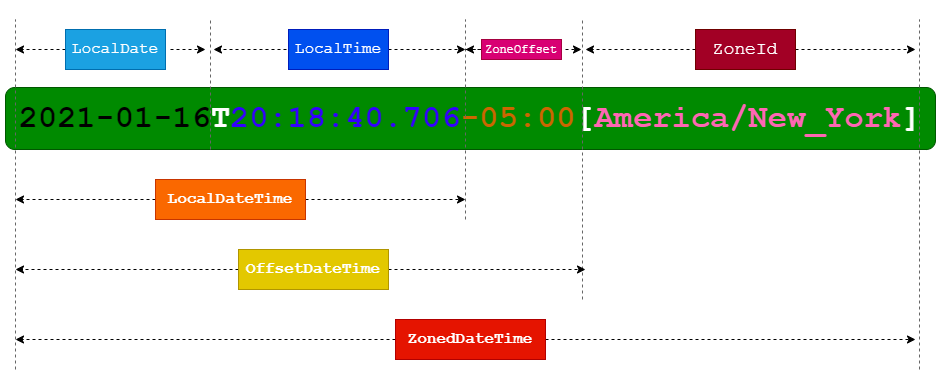
# (一)LocalDateTime 类
- now 获取时间
- toLocalDate 转换格式
- of 指定时间
- withXxx() 调整时间
- 使用 DateTimeFormatter 进行格式的转换
示例
// 自定义格式化: DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy/MM/dd HH:mm:ss"); System.out.println(dtf.format(LocalDateTime.now())); // 用自定义格式解析: LocalDateTime dt2 = LocalDateTime.parse("2019/11/30 15:16:17", dtf); System.out.println(dt2);1
2
3
4
5
6
7
# (二)ZonedDateTime 类
可以简单地把 ZonedDateTime 理解成 LocalDateTime 加 ZoneId。ZoneId 是 java.time 引入的新的时区类,注意和旧的 java.util.TimeZone 区别。
toInstant、toEpochSecond这两个方法会转换成 0 时区的对应时间。toLocalDataTime不会转时区,会直接丢弃时区信息。
# (三)DateTimeFormatter 类
# (四)Instant 类
Instant 时间不能设置时区,但是他是有时区的(only 0 时区)。
# IO
- flush(),强制刷新
- Class 对象的
getResourceAsStream()可以从classpath中读取指定资源;
# 流的重复读取
// TODO
# 序列化
# 简介
序列化是指把一个 Java 对象变成二进制内容,本质上就是一个 byte[] 数组。
为什么要把 Java 对象序列化呢?因为序列化后可以把 byte[] 保存到文件中,或者把 byte[] 通过网络传输到远程,这样,就相当于把 Java 对象存储到文件或者通过网络传输出去了。
有序列化,就有反序列化,即把一个二进制内容(也就是 byte[] 数组)变回 Java 对象。有了反序列化,保存到文件中的 byte[] 数组又可以“变回”Java 对象,或者从网络上读取 byte[] 并把它“变回” Java 对象。
# 为什么要序列化
无论什么编程语言,其底层涉及 IO 操作的部分还是由操作系统其帮其完成的,而底层 IO 操作都是以字节流的方式进行的, 所以写操作都涉及将编程语言数据类型转换为字节流,而读操作则又涉及将字节流转化为编程语言类型的特定数据类型。
# serialVersionUID
实现了 Serializable 接口的类,都需要指定一个 serialVersionUID。
例子:比如一个 Student 类的实例被实例化为一个 student.txt 文件(这个文件内会有这个实例的序列化 ID), 在反序列化的时候,会验证 txt 文件中的序列化 ID 是否和 Student 类中的 ID 一致,如果不一致,则序列化失败。
如果你不显示的声明一个 serialVersionUID,那么 Java 运行时环境会根据类的信息,自动生成个一个(如果后来你改变了类,比如改变了字段,这时候这个自动生成的 ID 就会跟着变化)。
一个实现了 Serializable 接口的类,都应该显示声明一个 serialVersionUID,这样的话,你的类的一个实例序列化成了一个文件以后,你改变了这个类的结构或信息(类改变以后,自动生成的 ID 会自动变化),这时反序列化的时候,就会反序列化失败,那么如果你显示的声明一个 ID,那么即使后来你改变了你的类结构,反序列化依旧可以成功,因为他们的 ID 没有变。
# 特殊情况
- 凡是被
static修饰的字段是不会被序列化的 - 凡是被
transient修饰符修饰的字段也是不会被序列化的
对于第一点,因为序列化保存的是对象的状态而非类的状态,所以会忽略 static 静态域也是理所应当的。
对于第二点,就需要了解一下 transient 修饰符的作用了。
如果在序列化某个类的对象时,就是不希望某个字段被序列化(比如这个字段存放的是隐私值,如:密码等),那这时就可以用 transient 修饰符来修饰该字段。
比如 private transient String password,被 transient 修饰的变量不会被序列化,它的值会被序列化为 null,反序列化以后得到的也是 null。
# JavaType
使用 Javatype 实现带有泛型的序列化。
JavaType javaType = objectMapper.getTypeFactory().constructParametricType(responseType, itemType);// 此处两个是 class
response = objectMapper.readValue(responseBodyString, javaType);
2
# JsonProperty
@JsonProperty(value="Key")
private String key;
2
# JsonInclude
使用 @JsonInclude 可以指定对象或者是指定变量的序列化方式。
# 反射
通过 Class 实例获取 class 信息的方法称为反射(Reflection)。
# Class 类
class 是由 JVM 在执行过程中动态加载的。JVM 在第一次读取到一种 class 类型时,将其加载进内存(method area)。
获取一个 class 的 Class 实例有三个方法:
直接通过一个 class 的静态变量 class 获取:
Class cls = String.class;
通过该实例变量提供的
getClass()方法获取:String s = "Hello"; Class cls = s.getClass();1
2如果知道一个 class 的完整类名,可以通过静态方法
Class.forName()获取:Class cls = Class.forName("java.lang.String");
PS:
Start:
-> .java 文件
-> .class 文件
-> (.class 文件)被 JVM 加载进内存(method area/static area)
-> JVM 第一次读取到一种 class 时,为它创建一个名为[文件名]的 Class 类型的 class,这个 class 包含了这个 class 文件的所有信息,
并且将这个 class 文件放进方法区,然后这个 xxxclass 作为这个类的各种数据的访问入口。
-> 在代码中通过获取一个类的 Class 实例 xxxclass,然后从这个 class 文件中读取这个类的信息的方式叫做反射
2
3
4
5
6
7
注意: 这里的 Class 本身也是一种 class 文件(Class.class 文件),只不过它的构造方法是 private,它只能由 JVM 创建。这个 Class 定义了一个类中应该有的所有信息变量,所以它可以将一个 class 文件的所有信息都加载进来,并在代码中使用。
# 访问字段
通过 Class 实例获取字段信息。
Field getField(name):根据字段名获取某个public的field(包括父类)Field getDeclaredField(name):根据字段名获取当前类的某个field(不包括父类)Field[] getFields():获取所有public的field(包括父类)Field[] getDeclaredFields():获取当前类的所有field(不包括父类)
# 多线程
# 多进程和多线程
多进程缺点:
- 创建进程比创建线程开销大,尤其是在 Windows 系统上;
- 进程间通信比线程间通信要慢,因为线程间通信就是读写同一个变量,速度很快。
多线程优点:
- 多进程稳定性比多线程高
- 多进程的情况下,一个进程崩溃不会影响其他进程。
- 多线程的情况下,任何一个线程崩溃会直接导致整个进程崩溃。
# 创建多线程
Java 创建多线程主要有 2 类,第一类是没有返回值的,也是最常见的方式。还有一种是有返回值的创建方式。
没有返回值的有 2 种方法:
- 继承
Tread类,然后覆写run方法,最后使用start方法执行。 - 实现
Runable接口,然后使用start方法进行执行。
建议使用第二种方法,因为类的继承为单继承,第 2 种可以避免不能继承其他的类。
示例:
// 第一种,继承 Tread 类
public class Main {
public static void main(String[] args) {
Thread t = new MyThread();
t.start(); // 启动新线程
}
}
class MyThread extends Thread {
@Override
public void run() {
System.out.println("start new thread!");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
// 第二种,实现 Runable 接口
public class Main {
public static void main(String[] args) {
Thread t = new Thread(new MyRunnable());
t.start(); // 启动新线程
}
}
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("start new thread!");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
需要返回值的创建方式:通过创建 Callable 接口和 Future 接口的方式来创建线程。
从上面两个例子我们可以看到,Runable 的方式执行的代码逻辑是没有返回值的,这样我们不能获取多线程方法的返回值。如果我们想要获取多线程执行结果就需要使用 Callable 结合 Future 的方式实现。
// Callable 和 Runable 是没有区别的,只是一个有返回值,一个不支持返回值
public static void main(String[] args) throws ExecutionException, InterruptedException {
// myCallable 是要执行的任务
MyCallable myCallable = new MyCallable();
// futureTask 是用来管理多线程运行的结果的
FutureTask<Integer> futureTask = new FutureTask<>(myCallable);
Thread t1 = new Thread(futureTask);
t1.start();
System.out.println(futureTask.get());
}
public static class MyCallable implements Callable<Integer> {
@Override
public Integer call() {
return 1 + 1;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 线程常用方法
setDeamonyieldjoin
# 线程优先级
Thread.setPriority(int n),1 ~ 10, 默认值 5,1 为最低。- 优先级高的只意味着更频繁的 CPU 调度,而不是说优先级高的就要比优先级低的早执行。
# 线程状态
下图中,运行状态不属于 Java 定义的线程状态中的一种。运行状态表示已经在 CPU 中运行,这时候的状态并不是 Java 本身关注的。
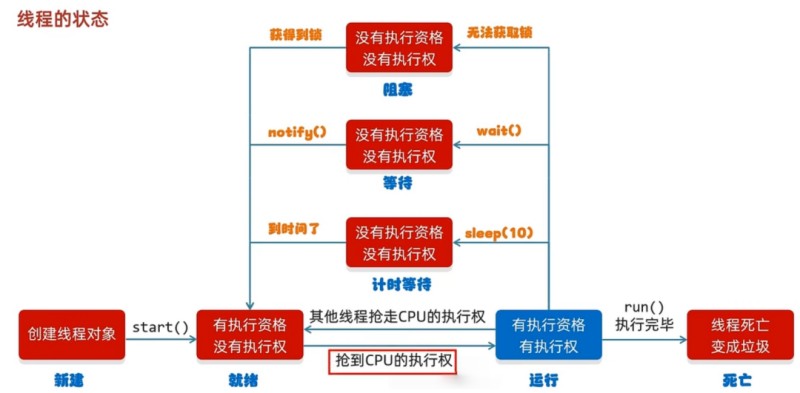
在 Java 程序中,一个线程对象只能调用一次 start() 方法启动新线程,并在新线程中执行 run() 方法。一旦 run() 方法执行完毕,线程就结束了。因此,Java 线程的状态有以下几种:
New,新创建的线程,尚未执行;Runnable,运行中的线程,正在抢占 CPU 中,然后去执行run()方法的 Java 代码;Blocked,运行中的线程,因为某些操作被阻塞而挂起;Waiting,运行中的线程,因为某些操作在等待中;Timed Waiting,运行中的线程,因为执行sleep()方法正在计时等待;Terminated,线程已终止,因为run()方法执行完毕。
线程终止的原因有:
- 线程正常终止:
run()方法执行到return语句返回; - 线程意外终止:
run()方法因为未捕获的异常导致线程终止; - 对某个线程的
Thread实例调用stop()方法强制终止(强烈不推荐使用)。 join()可以使得当前线程的方法优先执行。
# 中断线程
- 使用
interrupt()中断线程,使用isInterrupted()检测是否中断;
volatile 关键字的目的是告诉虚拟机:
- 每次访问变量时,总是获取主内存的最新值;
- 每次修改变量后,立刻回写到主内存。
# 守护线程
直白讲就是,在线程 A 里创建一个守护线程 B,如果线程 A 结束了,无论线程 B 当前状态如何,B 都会结束。因为 B 是 A 的守护线程,当失去了被守护者 A 的时候,线程 B 也就没有存在的必要了。
Daemon Thread,守护线程是指为其他线程服务的线程。在 JVM 中,所有非守护线程都执行完毕后,无论有没有守护线程,虚拟机都会自动退出。因此,JVM 退出时,不必关心守护线程是否已结束。
创建方式: 在调用 start() 方法前,调用 setDaemon(true) 把该线程标记为守护线程。
Thread t = new MyThread();
t.setDaemon(true);
t.start();
2
3
注意:
- 在 Daemon 线程中产生的新线程也是 Daemon 的。
- 守护线程不能持有任何需要关闭的资源,例如打开文件等,因为虚拟机退出时,守护线程没有任何机会来关闭文件,这会导致数据丢失。
# 线程同步
加锁与解锁之间的代码块--临界区
# 加锁
synchronized 锁是可重入锁;
我们来概括一下如何使用 synchronized:
- 找出修改共享变量的线程代码块;
- 选择一个共享实例作为锁;
- 使用
synchronized(lockObject) { ... }。
不需要 synchronized 的操作
JVM 规范定义了几种原子操作:
- 基本类型(
long和double除外)赋值,例如:int n = m; - 引用类型赋值,例如:
List<String> list = anotherList。
# 死锁
如何避免死锁呢?
- 线程获取锁的顺序要一致。
# wait 和 notify
wait()方法必须在当前获取的锁对象上调用,这里获取的是this锁,因此调用this.wait()。wait()方法调用时,会释放线程获得的锁,wait()方法返回后,线程又会重新试图获得锁。- 如何让等待的线程被重新唤醒,然后从
wait()方法返回?- 答案是在相同的锁对象上调用
notify()方法。
- 答案是在相同的锁对象上调用
# 线程池
ExecutorService 接口表示线程池
线程池的初始化
ExecutorService 只是接口,Java 标准库提供的几个常用实现类有:
FixedThreadPool:线程数固定的线程池;CachedThreadPool:线程数根据任务动态调整的线程池;SingleThreadExecutor:仅单线程执行的线程池。
创建这些线程池的方法都被封装到 Executors 这个类中。
线程池的使用
- 使用
submit()方法提交任务,提交的任务是已经实现了 Runnable 接口的类。
线程池的关闭
- 使用
shutdown()方法关闭线程池- 它会等待正在执行的任务先完成,然后再关闭。
shutdownNow()会立刻停止正在执行的任务awaitTermination()则会等待指定的时间让线程池关闭。
示例:
ExecutorService es = Executors.newFixedThreadPool(5);
for (int i = 0; i < 7; i++) {
es.submit(new Task("第" + i + "个任务"));
}
es.shutdown();
2
3
4
5
class Task implements Runnable {
private String name;
public Task(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println("启动了" + name);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
return;
}
System.out.println("结束" + name);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# ThreadLocal
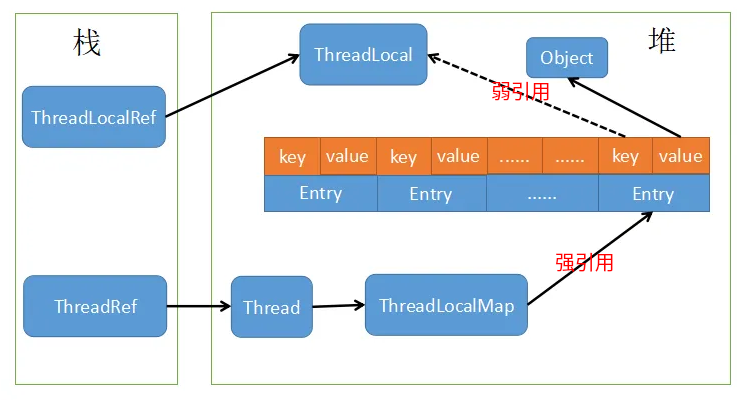
ThreadLocal 类型变量实现变量为线程私有,原理是使用了 ThreadLocalMap。
使用时,将 ThreadLocal 对象作为 Map 的 key,将要存储的值作为 value 存起来,这样每个线程访问的都是当前线程的值了,也就不再存在线程安全问题。
# Java 四种引用
- 强引用
- 只要有指针指向了这个对象,那么这个对象永远都不会被回收。例如
User user = new User();
- 只要有指针指向了这个对象,那么这个对象永远都不会被回收。例如
- 软引用
- 还有用处,JVM 会在内存溢出时清理这部分。例如:缓存
- 弱引用
- 引用关系弱于软引用,不管内存是否够用,下次 GC 一定会回收
- 虚引用
- 不会影响对象的回收,唯一作用是对象被回收时会受到一个系统通知
# 内存泄漏问题
首先说一个名词 OOM,即 Out Of Memory,内存泄露、内存溢出。
ThreadLocal 中的 key 是弱引用,value 是强引用。key 是每个 Thread 中的 TreadLocal 对象本身(如果没有强引用指向它,它就会被 GC 回收):
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
// 看这里的 super(),表示 key 是一个弱引用。
super(k);
value = v;
}
}
2
3
4
5
6
7
8
9
10
而 value 被 Entry 强引用不会被回收,具体应该是 thread ref -> thread -> threadLocals -> entry -> value,这时导致 value 成为了一个无法访问也不能被回收的对象,这就造成了内存泄露。
如果当前线程很快结束的话,最终 value 也会被回收,但是由于线程频繁的创建和销毁会占用大量资源,所以一般会使用线程池,那么线程就可能会很长时间不被销毁,那么 value 也就一直不会被回收。
# 解决方法
- 使用 static final,避免重复创建销毁 ThreadLocal 对象。
- 使用 remove() 方法,手动清除 ThreadLocal 对象。
其实 ThreadLocal 对象的 get() / set() / remove() 方法的具体实现中,都做了进一步的处理,进一步的避免了 OOM 的情况。
# 示例
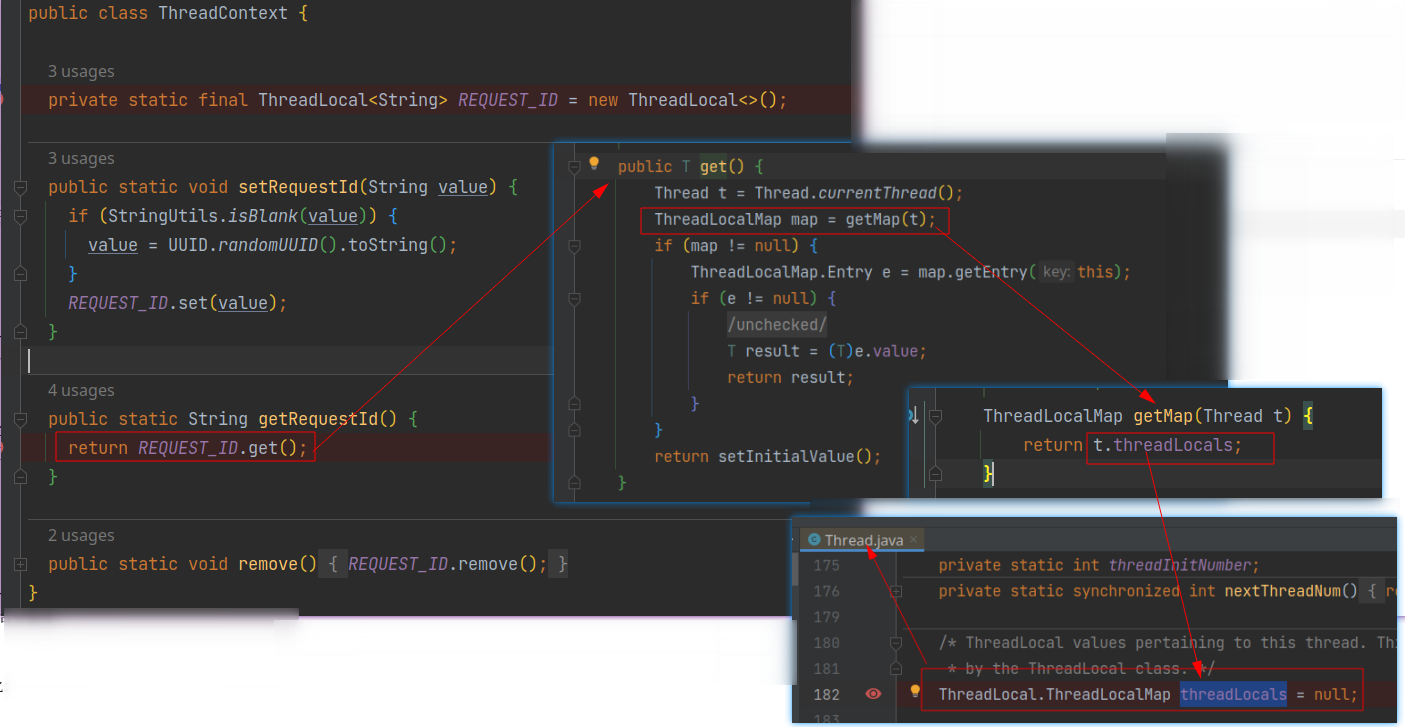
ThreadLocal 可以理解为是一个可以操作 Thread 上的那个 map 的工具类而已,因为每个线程拿到的 map 都是当前线程私有的。不要去想那个线程变量(REQUEST_ID)就一个,它的确就一个,它的作用是指定要拿哪个值,通过它操作的值(值所在的 map)存在于 Thread 上,这个线程变量只是个媒介而已。
# 讨论区
由于评论过多会影响页面最下方的导航,故将评论区做默认折叠处理。