
# Java 多线程
# 参考文档
# 多线程
# 多进程和多线程
多进程缺点:
- 创建进程比创建线程开销大,尤其是在 Windows 系统上;
- 进程间通信比线程间通信要慢,因为线程间通信就是读写同一个变量,速度很快。
多线程优点:
- 多进程稳定性比多线程高
- 多进程的情况下,一个进程崩溃不会影响其他进程。
- 多线程的情况下,任何一个线程崩溃会直接导致整个进程崩溃。
# 创建多线程
Java 创建多线程主要有 2 类,第一类是没有返回值的,也是最常见的方式。还有一种是有返回值的创建方式。
没有返回值的有 2 种方法:
- 继承
Tread类,然后覆写run方法,最后使用start方法执行。 - 实现
Runable接口,然后使用start方法进行执行。
建议使用第二种方法,因为类的继承为单继承,第 2 种可以避免不能继承其他的类。
示例:
// 第一种,继承 Tread 类
public class Main {
public static void main(String[] args) {
Thread t = new MyThread();
t.start(); // 启动新线程
}
}
class MyThread extends Thread {
@Override
public void run() {
System.out.println("start new thread!");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
// 第二种,实现 Runable 接口
public class Main {
public static void main(String[] args) {
Thread t = new Thread(new MyRunnable());
t.start(); // 启动新线程
}
}
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("start new thread!");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
需要返回值的创建方式:通过创建 Callable 接口和 Future 接口的方式来创建线程。
从上面两个例子我们可以看到,Runable 的方式执行的代码逻辑是没有返回值的,这样我们不能获取多线程方法的返回值。如果我们想要获取多线程执行结果就需要使用 Callable 结合 Future 的方式实现。
// Callable 和 Runable 是没有区别的,只是一个有返回值,一个不支持返回值
public static void main(String[] args) throws ExecutionException, InterruptedException {
// myCallable 是要执行的任务
MyCallable myCallable = new MyCallable();
// futureTask 是用来管理多线程运行的结果的
FutureTask<Integer> futureTask = new FutureTask<>(myCallable);
Thread t1 = new Thread(futureTask);
t1.start();
System.out.println(futureTask.get());
}
public static class MyCallable implements Callable<Integer> {
@Override
public Integer call() {
return 1 + 1;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 线程常用方法
setDeamonyieldjoin
# 线程优先级
Thread.setPriority(int n),1 ~ 10, 默认值 5,1 为最低。- 优先级高的只意味着更频繁的 CPU 调度,而不是说优先级高的就要比优先级低的早执行。
# 线程状态
下图中,运行状态不属于 Java 定义的线程状态中的一种。运行状态表示已经在 CPU 中运行,这时候的状态并不是 Java 本身关注的。
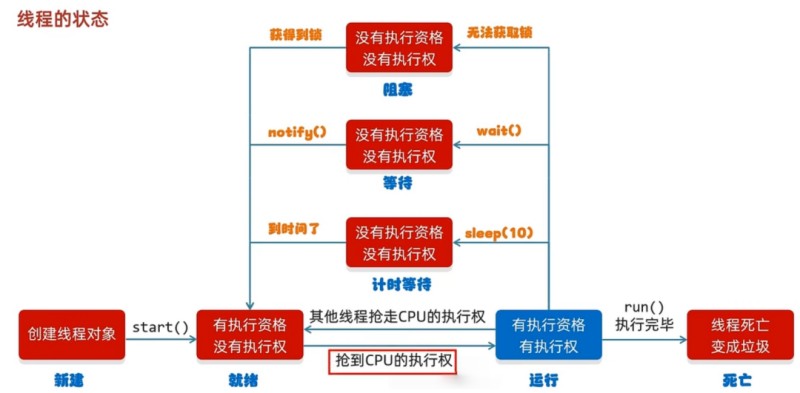
在 Java 程序中,一个线程对象只能调用一次 start() 方法启动新线程,并在新线程中执行 run() 方法。一旦 run() 方法执行完毕,线程就结束了。因此,Java 线程的状态有以下几种:
New,新创建的线程,尚未执行;Runnable,运行中的线程,正在抢占 CPU 中,然后去执行run()方法的 Java 代码;Blocked,运行中的线程,因为某些操作被阻塞而挂起;Waiting,运行中的线程,因为某些操作在等待中;Timed Waiting,运行中的线程,因为执行sleep()方法正在计时等待;Terminated,线程已终止,因为run()方法执行完毕。
线程终止的原因有:
- 线程正常终止:
run()方法执行到return语句返回; - 线程意外终止:
run()方法因为未捕获的异常导致线程终止; - 对某个线程的
Thread实例调用stop()方法强制终止(强烈不推荐使用)。 join()可以使得当前线程的方法优先执行。
# 中断线程
- 使用
interrupt()中断线程,使用isInterrupted()检测是否中断;
volatile 关键字的目的是告诉虚拟机:
- 每次访问变量时,总是获取主内存的最新值;
- 每次修改变量后,立刻回写到主内存。
# 守护线程
直白讲就是,在线程 A 里创建一个守护线程 B,如果线程 A 结束了,无论线程 B 当前状态如何,B 都会结束。因为 B 是 A 的守护线程,当失去了被守护者 A 的时候,线程 B 也就没有存在的必要了。
Daemon Thread,守护线程是指为其他线程服务的线程。在 JVM 中,所有非守护线程都执行完毕后,无论有没有守护线程,虚拟机都会自动退出。因此,JVM 退出时,不必关心守护线程是否已结束。
创建方式: 在调用 start() 方法前,调用 setDaemon(true) 把该线程标记为守护线程。
Thread t = new MyThread();
t.setDaemon(true);
t.start();
2
3
注意:
- 在 Daemon 线程中产生的新线程也是 Daemon 的。
- 守护线程不能持有任何需要关闭的资源,例如打开文件等,因为虚拟机退出时,守护线程没有任何机会来关闭文件,这会导致数据丢失。
# 线程同步
加锁与解锁之间的代码块--临界区
# 加锁
synchronized 锁是可重入锁;
我们来概括一下如何使用 synchronized:
- 找出修改共享变量的线程代码块;
- 选择一个共享实例作为锁;
- 使用
synchronized(lockObject) { ... }。
不需要 synchronized 的操作
JVM 规范定义了几种原子操作:
- 基本类型(
long和double除外)赋值,例如:int n = m; - 引用类型赋值,例如:
List<String> list = anotherList。
# 死锁
如何避免死锁呢?
- 线程获取锁的顺序要一致。
# wait 和 notify
wait()方法必须在当前获取的锁对象上调用,这里获取的是this锁,因此调用this.wait()。wait()方法调用时,会释放线程获得的锁,wait()方法返回后,线程又会重新试图获得锁。- 如何让等待的线程被重新唤醒,然后从
wait()方法返回?- 答案是在相同的锁对象上调用
notify()方法。
- 答案是在相同的锁对象上调用
# 线程池
ExecutorService 接口表示线程池
线程池的初始化
ExecutorService 只是接口,Java 标准库提供的几个常用实现类有:
FixedThreadPool:线程数固定的线程池;CachedThreadPool:线程数根据任务动态调整的线程池;SingleThreadExecutor:仅单线程执行的线程池。
创建这些线程池的方法都被封装到 Executors 这个类中。
线程池的使用
- 使用
submit()方法提交任务,提交的任务是已经实现了 Runnable 接口的类。
线程池的关闭
- 使用
shutdown()方法关闭线程池- 它会等待正在执行的任务先完成,然后再关闭。
shutdownNow()会立刻停止正在执行的任务awaitTermination()则会等待指定的时间让线程池关闭。
示例:
ExecutorService es = Executors.newFixedThreadPool(5);
for (int i = 0; i < 7; i++) {
es.submit(new Task("第" + i + "个任务"));
}
es.shutdown();
2
3
4
5
class Task implements Runnable {
private String name;
public Task(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println("启动了" + name);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
return;
}
System.out.println("结束" + name);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# ThreadLocal
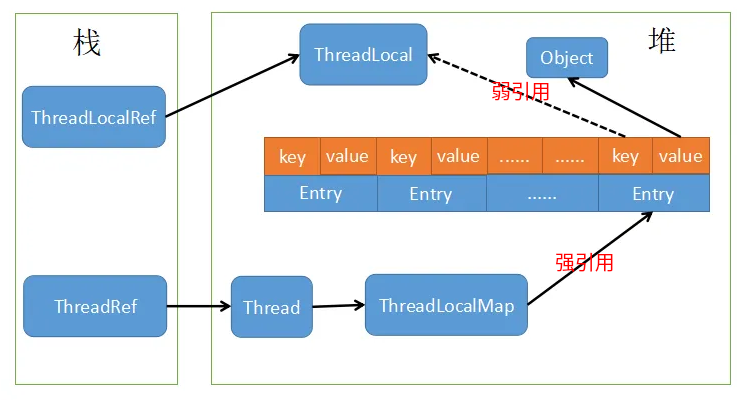
ThreadLocal 类型变量实现变量为线程私有,原理是使用了 ThreadLocalMap。
使用时,将 ThreadLocal 对象作为 Map 的 key,将要存储的值作为 value 存起来,这样每个线程访问的都是当前线程的值了,也就不再存在线程安全问题。
# Java 四种引用
- 强引用
- 只要有指针指向了这个对象,那么这个对象永远都不会被回收。例如
User user = new User();
- 只要有指针指向了这个对象,那么这个对象永远都不会被回收。例如
- 软引用
- 还有用处,JVM 会在内存溢出时清理这部分。例如:缓存
- 弱引用
- 引用关系弱于软引用,不管内存是否够用,下次 GC 一定会回收
- 虚引用
- 不会影响对象的回收,唯一作用是对象被回收时会受到一个系统通知
# 内存泄漏问题
首先说一个名词 OOM,即 Out Of Memory,内存泄露、内存溢出。
ThreadLocal 中的 key 是弱引用,value 是强引用。key 是每个 Thread 中的 TreadLocal 对象本身(如果没有强引用指向它,它就会被 GC 回收):
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
// 看这里的 super(),表示 key 是一个弱引用。
super(k);
value = v;
}
}
2
3
4
5
6
7
8
9
10
而 value 被 Entry 强引用不会被回收,具体应该是 thread ref -> thread -> threadLocals -> entry -> value,这时导致 value 成为了一个无法访问也不能被回收的对象,这就造成了内存泄露。
如果当前线程很快结束的话,最终 value 也会被回收,但是由于线程频繁的创建和销毁会占用大量资源,所以一般会使用线程池,那么线程就可能会很长时间不被销毁,那么 value 也就一直不会被回收。
# 解决方法
- 使用 static final,避免重复创建销毁 ThreadLocal 对象。
- 使用 remove() 方法,手动清除 ThreadLocal 对象。
其实 ThreadLocal 对象的 get() / set() / remove() 方法的具体实现中,都做了进一步的处理,进一步的避免了 OOM 的情况。
# 示例
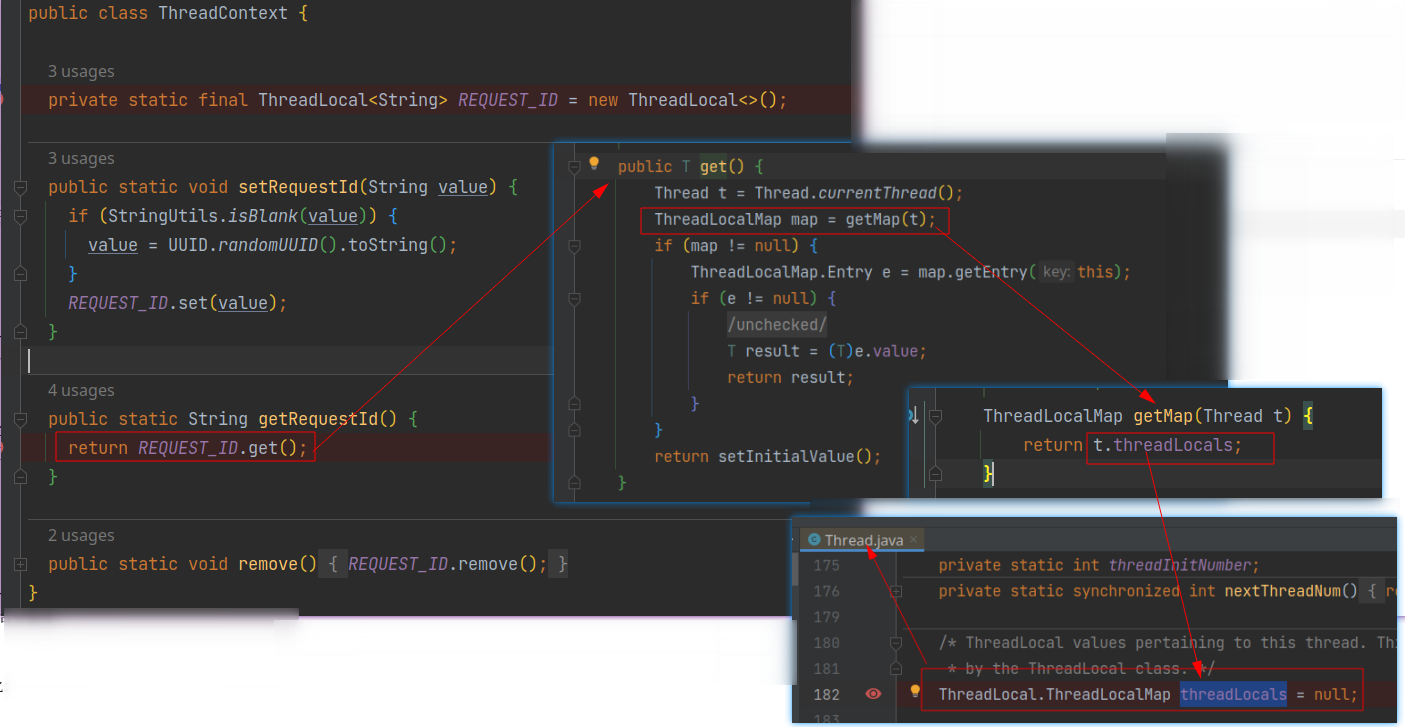
ThreadLocal 可以理解为是一个可以操作 Thread 上的那个 map 的工具类而已,因为每个线程拿到的 map 都是当前线程私有的。不要去想那个线程变量(REQUEST_ID)就一个,它的确就一个,它的作用是指定要拿哪个值,通过它操作的值(值所在的 map)存在于 Thread 上,这个线程变量只是个媒介而已。
# 讨论区
由于评论过多会影响页面最下方的导航,故将评论区做默认折叠处理。